

Given the trend around microservices, it has become mandatory to be able to follow a transaction across multiple microservices.
Spring Cloud Sleuth is such a distributed tracing system fully integrated into the Spring Boot ecosystem.
By adding the spring-cloud-starter-sleuth into a project’s POM, it instantly becomes Sleuth-enabled and every standard log call automatically adds additional data, such as spanId and traceId to the usual data.
2016-11-25 19:05:53.221 INFO [demo-app,b4d33156bc6a49ec,432b43172c958450,false] 25305 ---\n [nio-8080-exec-1] ch.frankel.blog.SleuthDemoApplication : this is an example message
| Broken on 2 lines for better readability |
Now, instead of sending the data to Zipkin, let’s say I need to store it into Elasticsearch instead. A product is as good as the way it’s used. Indexing unstructured log messages is not very useful. Logstash configuration allows to pre-parse unstructured data and send structured data instead.
Grok
Grokking data is the usual way to structure data with pattern matching.
Last week, I wrote about some hints for the configuration. Unfortunately, the hard part comes in writing the matching pattern itself, and those hints don’t help. While it might be possible to write a perfect Grok pattern on the first draft, the above log is complicated enough that it’s far from a certainty, and chances are high to stumble upon such message when starting Logstash with an unfit Grok filter:
"tags" => [
[0] "_grokparsefailure"
]However, there’s "an app for that" (sounds familiar?). It offers three fields:
- The first field accepts one (or more) log line(s)
- The second the grok pattern
- The 3rd is the result of filtering the 1st by the 2nd
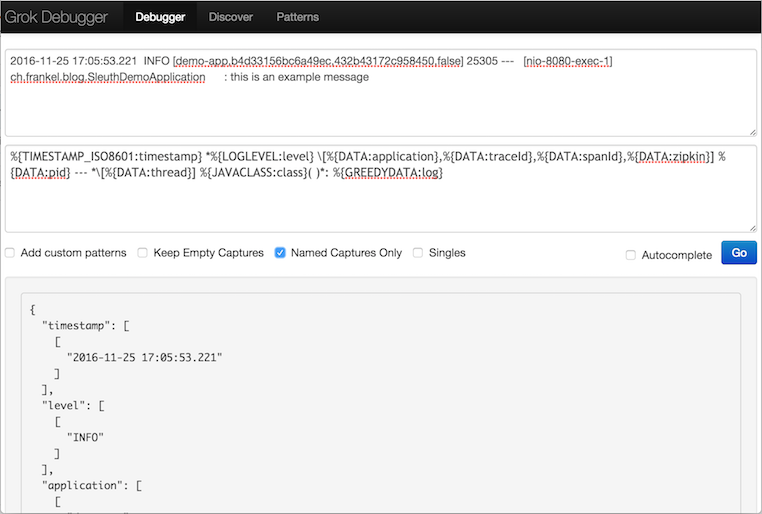
The process is now to match fields one by one, from left to right.
The first data field .e.g. 2016-11-25 19:05:53.221 is obviously a timestamp.
Among common grok patterns, it looks as if the TIMESTAMP_ISO8601 pattern would be the best fit.
Enter %{TIMESTAMP_ISO8601:timestamp} into the Pattern field.
The result is:
{
"timestamp": [
[
"2016-11-25 17:05:53.221"
]
]
}The next field to handle looks like the log level.
Among the patterns, there’s one LOGLEVEL.
The Pattern now becomes %{TIMESTAMP_ISO8601:timestamp} *%{LOGLEVEL:level} and the result:
{
"timestamp": [
[
"2016-11-25 17:05:53.221"
]
],
"level": [
[
"INFO"
]
]
}Rinse and repeat until all fields have been structured. Given the initial log line, the final pattern should look something along those lines:
%{TIMESTAMP_ISO8601:timestamp} *%{LOGLEVEL:level} \[%{DATA:application},%{DATA:traceId},%{DATA:spanId},%{DATA:zipkin}]\n
%{DATA:pid} --- *\[%{DATA:thread}] %{JAVACLASS:class} *: %{GREEDYDATA:log}| Broken on 2 lines for better readability |
And the associated result:
{
"traceId" => "b4d33156bc6a49ec",
"zipkin" => "false",
"level" => "INFO",
"log" => "this is an example message",
"pid" => "25305",
"thread" => "nio-8080-exec-1",
"tags" => [],
"spanId" => "432b43172c958450",
"path" => "/tmp/logstash.log",
"@timestamp" => 2016-11-26T13:41:07.599Z,
"application" => "demo-app",
"@version" => "1",
"host" => "LSNM33795267A",
"class" => "ch.frankel.blog.SleuthDemoApplication",
"timestamp" => "2016-11-25 17:05:53.221"
}
Dissect
The Grok filter gets the job done.
But it seems to suffer from performance issues, especially if the pattern doesn’t match.
An alternative is to use the dissect filter instead, which is based on separators.
Unfortunately, there’s no app for that - but it’s much easier to write a separator-based filter than a regex-based one. The mapping equivalent to the above is:
%{timestamp} %{+timestamp} %{level}[%{application},%{traceId},%{spanId},%{zipkin}]\n
%{pid} %{}[%{thread}] %{class}:%{log}| Broken on 2 lines for better readability |
This outputs the following:
{
"traceId" => "b4d33156bc6a49ec",
"zipkin" => "false",
"log" => " this is an example message",
"level" => "INFO ",
"pid" => "25305",
"thread" => "nio-8080-exec-1",
"tags" => [],
"spanId" => "432b43172c958450",
"path" => "/tmp/logstash.log",
"@timestamp" => 2016-11-26T13:36:47.165Z,
"application" => "demo-app",
"@version" => "1",
"host" => "LSNM33795267A",
"class" => "ch.frankel.blog.SleuthDemoApplication ",
"timestamp" => "2016-11-25 17:05:53.221"
}
Notice the slight differences: by moving from a regex-based filter to a separator-based one, some strings end up padded with spaces. There are 2 ways to handle that:
- change the logging pattern in the application - which might make direct log reading harder
- strip additional spaces with Logstash
With the second option, the final filter configuration snippet is:
filter {
dissect {
mapping => { "message" => ... }
}
mutate {
strip => [ "log", "class" ]
}
}Conclusion
In order to structure data, the grok filter is powerful and used by many.
However, depending on the specific log format to parse, writing the filter expression might be quite complex a task.
The dissect filter, based on separators, is an alternative that makes it much easier - at the price of some additional handling.
It also is an option to consider in case of performance issues.