
Object-Oriented Programming advocates for modularization in order to build small and reusable components. There are however other reasons for this. In the case of the Spring framework, modularization enables Integration Testing, the ability to test the system or parts of it, including assembly configuration.
Why is it so important to test the system assembled with the final configuration? Let’s take a simple example, the making of a car. Unit Testing the car would be akin to testing every nuts and bolts of the car separately, while Integration Testing the car would be like driving it on a circuit. By testing only the car’s components separately, selling the assembled car is a huge risk as nothing guarantees it will behave correctly in real-life conditions.
Now that we have asserted Integration Testing is necessary to guarantee the adequate level of internal quality, it’s time to enable Integration Testing with the Spring framework. Integration Testing is based on the notion of SUT. Defining the SUT is to define the boundaries between what is tested and its dependencies. In nearly all cases, test setup will require to provide some kind of test double for each required dependency. Configuring those test doubles can only be achieved by modularizing Spring configuration, so that they can replace dependent beans located outside the SUT.

Spring’s DI configuration comes in 3 different flavors: XML - the legacy way, autowiring and the newest JavaConfig. We’ll have a look at how modularization can be achieved for each flavor. Mixed DI modularization can be deduced from each separate entry.
Autowiring
Autowiring is an easy way to assemble Spring applications.
It is achieved through the use of either @Autowiring or @Inject.
Let’s cover quickly autowiring: as injection is implicit, there’s no easy way to modularize configuration.
Applications using autowiring will just have to migrate to another DI flavor to allow for Integration Testing.
XML
XML is the legacy way to inject dependencies, but is still in use. Consider the following monolithic XML configuration file:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:jee="http://www.springframework.org/schema/jee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/jee
http://www.springframework.org/schema/jee/spring-jee.xsd">
<jee:jndi-lookup id="dataSource" jndi-name="jdbc/MyDataSource" />
<bean id="productRepository" class="ProductRepository">
<constructor-arg ref="dataSource" />
</bean>
<bean id="customerRepository" class="CustomerRepository">
<constructor-arg ref="dataSource" />
</bean>
<bean id="orderRepository" class="OrderRepository">
<constructor-arg ref="dataSource" />
</bean>
<bean id="orderService" class="OrderService">
<constructor-arg ref="productRepository" index="0" />
<constructor-arg ref="customerRepository" index="1" />
<constructor-arg ref="orderRepository" index="2" />
</bean>
</beans>At this point, Integration Testing orderService is not easy as it should be.
In particular, we need to:
- Download the application server
- Configure the server for the
jdbc/MyDataSourcedata source - Deploy all classes to the server
- Start the server
- Stop the server After the test(s)
Of course, all previous tasks have to be automated! Though not impossible thanks to tools such as Arquillian, it’s contrary to the KISS principle. To overcome this problem and make our life (as well as test maintenance) easier in the process requires tooling and design. On the tooling part, we’ll be using a local database. Usually, such a database is of the in-memory kind e.g. H2. On the design part, his requires separating our beans by creating two different configuration fragments, one solely dedicated to the data source to be faked and the other one for the beans constituting the SUT.
Then, we’ll use a Maven classpath trick: Maven puts the test classpath in front of the main classpath when executing tests. This way, files found in the test classpath will "override" similarly-named files in the main classpath. Let’s create two configuration files fragments:
- The "real" JNDI datasource as in the monolithic configuration
<beans...> <jee:jndi-lookup id="dataSource" jndi-name="jdbc/MyDataSource" /> </beans> - The Fake datasource
<beans...> <bean id="dataSource" class="org.apache.tomcat.jdbc.pool.DataSource"> <property name="driverClassName" value="org.h2.Driver" /> <property name="url" value="jdbc:h2:~/test" /> <property name="username" value="sa" /> <property name="maxActive" value="1" /> </bean> </beans>
Note we are using a Tomcat datasource object, this requires the org.apache.tomcat:tomcat-jdbc:jar library on the test classpath.
Also note the maxActive property.
This reflects the maximum number of connections to the database.
It is advised to always set it to 1 for test scenarios so that connections pool exhaustion bugs can be checked as early as possible.
The final layout is the following:
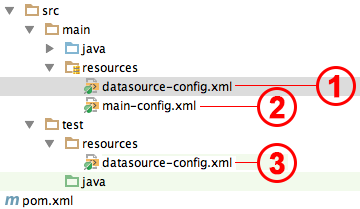
- JNDI datasource
- Other beans
- Fake datasource
The final main-config.xml file looks like:
<?xml version="1.0" encoding="UTF-8"?>
<beans...>
<import resource="classpath:datasource-config.xml" />
<!-- other beans go here -->
</beans>Such a structure is the basics to enable Integration Testing.
JavaConfig
JavaConfig is the most recent way to configure Spring applications, bringing both compile-time (as autowiring) and explicit configuration (as XML) safety.
The above datasources fragments can be "translated" in Java as follows:
- The "real" JNDI datasource as in the monolithic configuration
@Configuration public class DataSourceConfig { @Bean public DataSource dataSource() throws Exception { Context ctx = new InitialContext(); return (DataSource) ctx.lookup("jdbc/MyDataSource"); } } - The Fake datasource
public class FakeDataSourceConfig { public DataSource dataSource() { org.apache.tomcat.jdbc.pool.DataSource dataSource = new org.apache.tomcat.jdbc.pool.DataSource(); dataSource.setDriverClassName("org.h2.Driver"); dataSource.setUrl("jdbc:h2:~/test"); dataSource.setUsername("sa"); dataSource.setMaxActive(1); return dataSource; } }
However, there are two problems that appear when using JavaConfig.
- It’s not possible to use the same classpath trick with an import as with XML previously, as Java forbids to have 2 (or more) classes with the same qualified name loaded by the same classloader (which is the case with Maven).
Therefore, JavaConfig configuration fragments shouldn’t explicitly import other fragments but should leave the fragment assembly responsibility to their users (application or tests) so that names can be different, e.g.:
@ContextConfiguration(classes = {MainConfig.class, FakeDataSource.class}) public class SimpleDataSourceIntegrationTest extends AbstractTestNGSpringContextTests { @Test public void should_check_something_useful() { // Test goes there } } - The main configuration fragment uses the datasource bean from the other configuration fragment.
This mandates for the former to have a reference on the latter.
This is obtained by using the
@Autowiredannotation (one of the few relevant usage of it).@Configuration public class MainConfig { @Autowired private DataSource dataSource; // Other beans go there. They can use dataSource! }
Summary
In this article, I showed how Integration Testing to a Fake data source could be achieved by modularizing the monolithic Spring configuration into different configuration fragments, either XML or JavaConfig.
However, the realm of Integration Testing - with Spring or without, is vast. Should you want to go further, I’ll hold a talk on Integration Testing at Agile Tour London on Oct. 24th and at Java Days Kiev on Oct. 17th-18th.
This article is an abridged version of a part of the Spring chapter of Integration Testing from the Trenches. Have a look at it, there’s even a sample free chapter!
