In the previous article, I set up a cluster of 2 Tomcat instances in order to achieve load-balacing. It also offered failover capability. However, when using this feature, the user session was lost when changing node. In this article, I will show you how this side-effect can be avoided.
Reminder: the HTTP protocol is inherently disconnected (as opposed to FTP which is connected). In HTTP, the client sends a request to a server, it gets its response and that’s the end. The server cannot natively associate a request to a previous request made by the same client. In order to use HTTP for applications purpose, we needed to group such requests. Session is a label for this grouping feature.
This is done through a token, passed to the client on the first request. The token is passed with a cookie if possible, or appended to the URL if not. Interestingly enough, this is the same for PHP (token named PHPSESSID) as for JEE (token named JSESSIONID). In both case, we use a stateless protocol and tweak it so that it appears stateful. This pseudo-statefulness make possible application-level features, such as authentication/authorization or shopping cart.
Now, let’s take a real use case. I’m browsing through an online shop. I have already put some article in my cart. When I decide to finally go to the payment, I find myself with an empty basket! What happened? Unbeknownst to me, the node which hosted my session crashed and I was transparently rerouted to a working node, without my session ID, and thus, without the content of my cart.
Such thing can not happen in real life, since such a shop will probably be put out of business if this happens too often. There are basically 3 strategies to adopt in order to avoid such loss.
Sessions are evil
From time to time, I stumble upon articles blaming sessions and labeling them as evil. While not an universal truth, using sessions in a bad way can have negative side-effects.
The most representative bad usage of session if putting everything in them.
I’ve seen lazy developers put collections in session in order to manage paging.
You pass a statement once, put the result in the session, and manage paging on the sessionized result.
Since collection’s size is not constrained, such use does not scale well with the number of users increasing.
In most cases, everything goes fine in development but you’re soon overwhelmed by unusual response time or even OutOfMemoryError in production.
If you think sessions are evil, some solutions are:
- Store data in the database: now your data has to go from the front-end to the back-end to be saved, and then back again to be used. Classic relational database may not be the solution you’re looking for. Most high-traffic low-response time take the NoSQL route, although I don’t know if they use it for session storage purpose
- Store data on the client side through cookies: your clients needs to have cookie-enabled browser. Furthermore, data will be sent with every request/response so don’t overuse too much
The second option has the advantage of freeing you of session ID management. However, for both solution, your application code needs to implement the storage part.
Besides, nothing stops you from using sessions and using the extension points of your application server to use cookie storage instead of the default behaviour (mostly in memory). I wouldn’t recommend that though.
Server session replication
Another solution is to embrace session - this is a JEE feature after all - but to use session replication in order to avoid session data loss. Session replication is not a JEE feature. It is a proprietary feature, offered by many (if not all) application servers that is entirely independent from your code: your code uses session, and it is magically replicated by the server across cluster nodes.
There are two constraints common to session replication amongst all servers:
- Use the
<distributable />tag in the web.xml - Only put in session instances of classes that are
java.lang.Serializable
IMHO, these rules should be enforced on all web applications, whether currently deployed on a cluster or not, since they are not very restrictive. This way, deploying an application on a cluster will tends toward a no-operation.
Strategies available for session replication are application server dependent. However, they are usually based on the following implementations:
- In memory replication: each server stores all servers session data. When updating, it broadcasts to all nodes the modified session (or the delta, based on the strategy available/used). This implementation heavily uses the network and the memory
- Database persistence
- File persistence: the file system used should be available to all cluster nodes
For our simple example, I will just show you how to use in-memory session replication in Tomcat. The following are the steps one should take in order to do so. Please notice that one should first undertake what is described in the Tomcat clustering article.
|
Tomcat 5.5 has the cluster configuration commented in server.xml. Tomcat 6 does not. Here is the default clustering configuration: |
First, make sure that the mcastAddr and mcastPort of the <Membership> tag are the same.
This is validated when starting a second node with the following log in the first:
INFO: Replication member added:org.apache.catalina.cluster.mcast.McastMember[tcp ://10.138.97.43:4001,catalina,10.138.97.43,4001, alive=0]
This insures that all nodes of a cluster are able to communicate with each other. From this point on, considering all other configuration is left by default, sessions are replicated in memory in all nodes of the cluster. Thus, you don’t need sticky session anymore. This is not enough for failover though, since removing a node from the cluster will still lead a new request to be assigned a new session ID, thus preventing access to your previous session data.
In order to also route session IDs, you need to specify two additional tags in <Cluster>:
<Valve className="org.apache.catalina.cluster.session.JvmRouteBinderValve"
enabled="true" sessionIdAttribute="takeoverSessionid"/>
<ClusterListener className="org.apache.catalina.cluster.session.JvmRouteSessionIDBinderListener" />The valve redirects requests to another node with the previous session ID. The cluster listener receives session ID cluster change event. Now, removing a cluster node is seamless (apart from latency for redirected) for clients whose session ID was redirected to this node.
|
Last minute note
The previous setup uses the standard session manager. I was recently made aware of a third-party manager that also handles session cookies when a node fails, thus reducing the configuration hassle. Such product is Memcached Session Manager and is based on Memcached. Any feedback on the use of this product is welcome. |
Third party session replication
The previous solution has the disadvantage of specific server configuration. Though it does not impact development, it needs to be done for every server type in a different manner. This could be a burden if you happen to have different server types in your enterprise.
Using third party products is a remedy to this. Terracotta is such a product: morevoer, by providing a set number of Terracotta nodes, you avoid broadcasting your session changes to all server nodes, like in the Tomcat replication previous example.
In the following, the server is the Terracotta replication server and the clients are the Tomcat instances. In order to set up Terracotta, two steps are mandatory:
- create the configuration for the server.
In order to be used, name it tc-config.xml and put it in the bin directory.
In our case, this is it:
<tc:tc-config xmlns:tc="http://www.terracotta.org/config" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.terracotta.org/schema/terracotta-5.xsd"> ... <modules> <module name="tim-tomcat-5.5"/> </modules> ... <web-applications> <!-- The webapp(s) to watch --> <web-application>servlets-examples</web-application> </web-applications> ... </tc:tc-config>The default installed module is for Tomcat 6. In case you need the Tomcat 5.5 module, you have to launch the Terracotta Integration module Management (TIM) and use it to download the correct module. For users behind an Internet proxy, this is made possible by updating tim-get.properties with the following lines:
org.terracotta.modules.tool.proxyUrl = ... org.terracotta.modules.tool.proxyAuth = ... - add to all client launch scripts the following lines:
TC_INSTALL_DIR= TC_CONFIG_PATH=: . ${TC_INSTALL_DIR}/bin/dso-env.sh -q export JAVA_OPTS="$JAVA_OPTS $TC_JAVA_OPTS"
Now we’re back to session replication and failover but the configuration is usable across different application servers.
In order to see what is stored, you can also launch the Terracotta Developer Console.
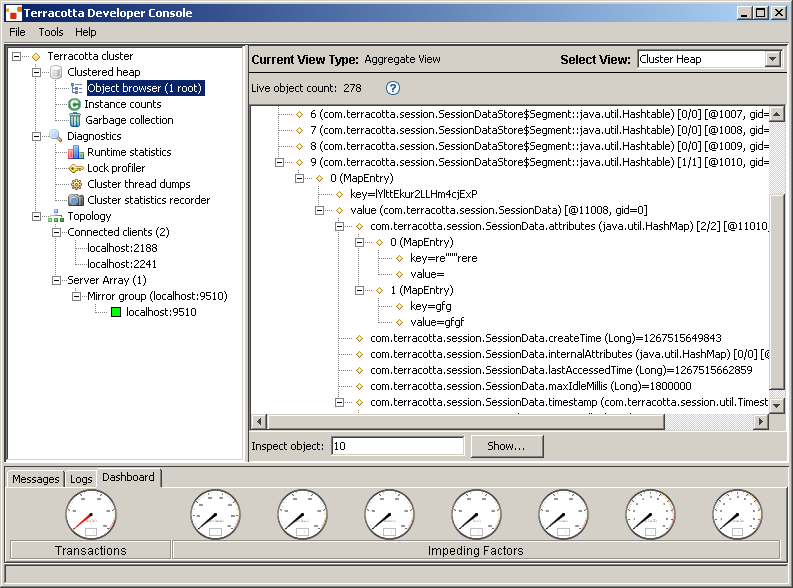
Conclusion
There are 3 basic strategies to manage session failover over cluster nodes. The first one is not to use session at all: it has major consequences on your development time, since your application has to do it directly. The second one is to look at the server documentation to look how it is done with a specific server. This ties your session management to a single product. Last but not least, you can use a third-party product. This has the advantage to move the configuration outside the scope of your specific server, thus letting you move with less hassle from one server to the next and still enjoy the benefits of session failover. Were I a system engineer, this is the solution I would recommend since it is the most flexible.